New Mexico Tech
Earth and Environmental Science
ERTH 455 / GEOP 555 - Geodetic Methods
Lab 4: gd2p.pl: static position estimation
UNAVCO bumper sticker
Note that you DO have to work on redoubt today!
Introduction
Last week you went through the exercise of determining a position from pseudoranges; basically by hand. Today we will start using GIPSY/OASIS (GPS Inferred Positioning SYstem and Orbit Analysis SImulation Software) for precise positioning. GIPSY is a collection of many programs and scripts to analyze GPS data (and other data).
Note that today focuses on setting you up for processing of GPS data. The processing will remain quite arbitrary and next week we'll move toward improving on this!
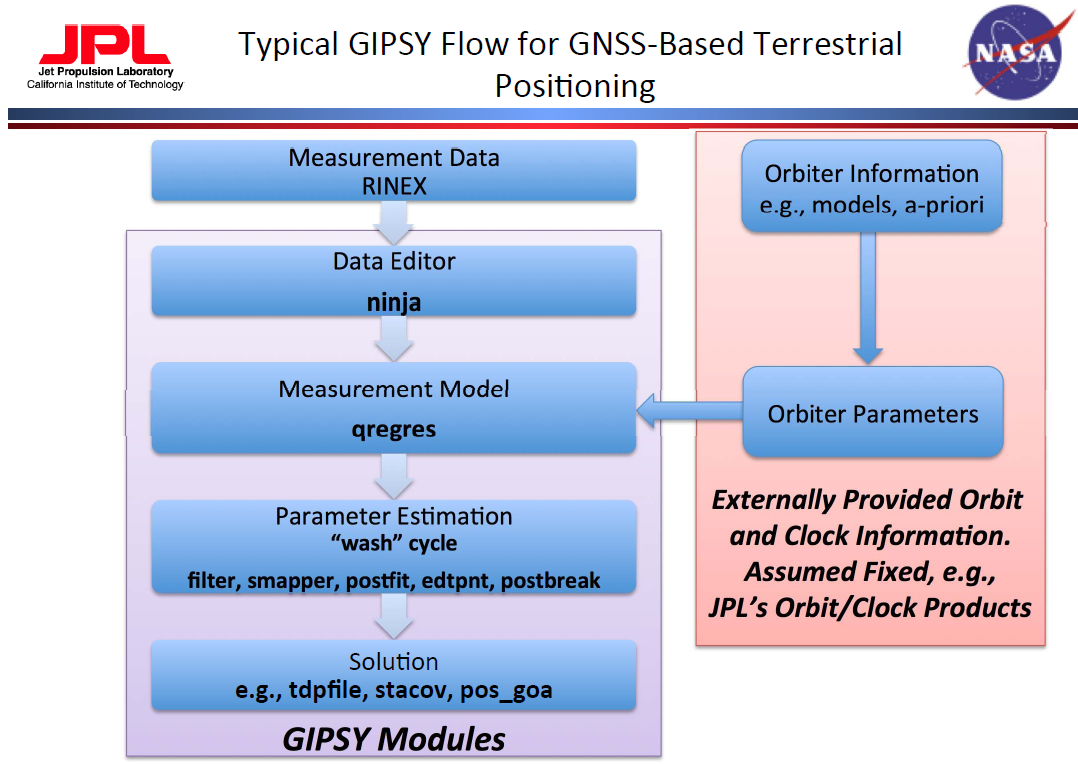
source: NASA/JPL
It is possible to string the programs together in a way that highly customizes your processing.
Obviously, that requires intimate familiarity with the tools so that you know exactly what
you're doing. gd2p.pl (GNSS data 2 Position) is a higher level interface to
GIPSY that allows you to process data for a single GPS/GLONASS receiver. It implements the
typical GIPSY workflow for kinematic and static positioning.
The command
$> gd2p.pl -h | moregives you full help and examples for this interface to GIPSY.
$> gd2p.pl -h_subGives a list of subtopics.
$> gd2p.pl -h_examplesGives a list of examples for different processing strategies.
In this lab, we can only cover some basics, I highly recommend that you take some time and explore this tool!
Setting things up: sta_info database and data files
Gipsy comes with a database, called sta_info that is composed of
several ASCII files; some we need to add information to be able to estimate positions for new stations. In my lab I keep
1 master copy of this database that contains the information for all the stations that
we process. Here, however, you will start out by creating your own copy.
- change into your working directory:
$> cd $GEOP555 - you should now be in a directory
/data/GEOP555/YOURNAME, where YOURNAME is your user name, if that's not true, go to LAB01 and fix your setup! (I did not do that for you when grading Lab01!) - copy the default instance of
sta_info:$> cp -r $GOA_VAR/sta_info . - an
$> ls -lisashould now list a directorysta_infoin your directory - the important files are
sta_id,sta_pos,sta_svec
These files are fixed format files! They have to match the format description EXACTLY!
Character by character, don't use tabs, no shortcuts or everything goes down the drain.
I've warned you!
From the documentation:
sta_id This file is the interface between the station identifiers in the database and the outside world. In this file, a given station name is associated with a station identifier and a station number. A given station identifier and station number can be associated with more than one station name. This is allowed so that multiple names for the same station can be handled. The station number is currently not used, but may be implemented in the future when all stations receive official GPS numbers. The following are examples of a few records: PENT 801 The following aliases for PENT were inserted on 9-May-1992 by fhw PENT 801 PENTICTON PENT 801 Penticton PENT 801 Penticton 1977 PENT 801 PGCQ PENT 801 A station somewhere in Canada GOLD 1437 DSS10 GOLD 1437 SPC10 GOLD 1437 Goldstone Rogue Antenna SDAD 202 USC&GS HORIZNOTAL CONTROL MARK SOLEDAD PEAK 1932 RM1 JPLM 7272 JPLMESA where PENT, GOLD, and SDAD are all station identifiers, 801, 1437, and 202 are the station numbers and the character strings are station names. These station names are the known aliases for this particular station and are case sensitive. The record format is: (1x,a4,i6,1x,a60) sta_pos This file associates the station identifier with the station coordinates at some epoch and the station velocity. An example of a record is: JPLM 1992 07 01 00:00:00.00 1000001.00 -2493304.0630 -4655215.5490 3565497.3390 -3.20000000e-02 1.90000000e-02 6.00000000e-03 Mon Nov 9 15:07:31 PST 1992 itrf91 1992.5 (The record is stored on one line.) The fields are: The station identifier; the epoch of the station coordinates (year, month, day, hours, minutes and seconds); the duration of the station coordinates (days); the station coordinates at the epoch (meters); the station velocities (meters/year); and a comment. The comment field could contain the reference system of the coordinates. The record format is: (1x,a4,1x,i4,4(1x,i2)1x,f5.2,1x,f10.2,1x,3f15.4,1x,3e15.8,1x,a30) sta_svec This file associates the station identifier with the site vector and antenna type at some epoch. An example of a record is: JPLM JPLM 1992 06 00 00:00:00.00 31536000.00 ROGUE 0.0000 0.0000 0.0000 0.1630 l 1992 07 06 (The record is stored on one line.) The fields are: the "to" station identifier; the "from" station identifier, the epoch of the site vector (year, month, day, hours, minutes and seconds); the duration (seconds), that the site vector is valid from the epoch; the antenna type, corresponding to one of the antenna types in the pcenter file; the station site vector; the antenna height; the site vector coordinate system flag, where c indicates Cartesian coordinates (XYZ) and l indicates local east-north-up coordinates (ENU); the date that the site vector was issued; and a comment. The record format is: (1x,a4,1x,a4,1x,i4,4(1x,i2)1x,f5.2,1x,f12.2,1x,a9,1x,4f11.4,1x,a1,1x,i4,1x,i2,1x,i2) (In this particular example, the "to" and "from" station identifiers are the same. This indicates that the site vector and antenna height in this record are for the offset between the JPLM antenna and the JPLM monument.)
Now for the data.
- We will use same RINEX file we've dealt with last time around: Abbott Peak on Ross Island, Antarctica
- I leave the organization of the data up to you, but I'd recommend you put this in a lab-specific directory and NOT into
sta_info - go to where ever you want to solve this lab and download the data
$> wget http://grapenthin.org/teaching/geop555/lab03/abbz2000.15o
Task 1: Update sta_info
Your first task is to add ABBZ to the database.
sta_id
- In the
sta_infodirectory, add a line tosta_id - The 4 character ID is
ABBZ, the number can be zero, the ID should be descriptive; maybeAbbott Peak, Ross Island, Antarctica
sta_pos
- You'd best copy and paste a line and then edit that!
- The 4 character ID is again
ABBZ, the next columns are date/time. The rinex file is for 2015-07-19, which is a good start date to use - in the directory where you stored the rinex file run:
$> grep APPROX abbz2000.15o - copy the first 3 numbers, which are the apriori position we've used last week - see where this is going?
- paste the apriori position into the respective columns and make the decimal points align (make sure your precision is only 4 decimal places)
- The next 3 columns are a velocity, which we don't have, so set that to zero, make sure all the decimal points align within each column
- At the end add a comment that this estimate comes from the rinex file abbz2000.15o (not more than 30 characters though!!)
sta_svec
- You'd best copy and paste a line and then edit that, again!
- The first 2 columns are BOTH
ABBZ - Then you add the date, 2015-07-19, which is the day we're looking at
- Set hours, minutes, seconds to zero
- Use a large number for the numbers of epochs this record is valid:
946080000.00 - Then add the first 9 character of the antenna type. Many, but not all rinex files come with the antenna type:
$> grep ANT abbz2000.15o - It should start with
TRM; when you copy it,you may have to shorten; make sure that the first character aligns with the others above and below and truncate until the last character also aligns. - The last columns should all be zero and 'l', the last column can be a comment on where you got this information (abbz2000.15o)
Note that some of that information is time dependent. With this setup, if you were to try to process data from before 2015-07-19, you'd be out of luck! GIPSY doesn't have any information about the site in the database and you'll have to update it. If you do that, you'll have to recalculate and update the valid times for some of the existing entries - that's important! But we don't have to deal with this right now.
Task 2: Process
By default gd2p.pl will fetch orbit files from JPL's ftp server. We'll run several runs
on the same data and don't need to download the same file over and over again. Execute the following
commands (in the directory you'll be using in this lab, I will refer to this as $WORKDIR):
$> mkdir orbit $> cd orbit $> goa_prod_ftp.pl -d 2015-07-19 -s flinnR -hrOK, now we're ready to run the first run (there will be many this week and next week).
$> cd $WORKDIR
$> mkdir run1 && cd run1
$> ( gd2p.pl -i $WORKDIR/abbz2000.15o -n ABBZ -d 2015-07-19 -r 300 \
-type s -w_elmin 15 -e "-a 20 -PC -LC -F" -pb_min_slip 1.0e-3 \
-pb_min_elev 30 -amb_res 2 -dwght 1.0e-5 1.0e-3 \
-post_wind 5.0e-3 5.0e-5 -trop_z_rw -1.0 -tides \
-orb_clk "flinnR $WORKDIR/orbit" > run1.log ) > & run1.err
That's quite a mouthful, isn't it? A lot of the options here are default values, but this
should demonstrate that there are many knobs you can turn to improve your position (or make it
worse).
The options are:
-i input RINEX file, including path
-n name of site (used in sta_info)
-d date to process (used to get orbit, clock products)
-r measurement data rate for data editor to output into filter
-type type of positioning (s - static, k-kinematic)
-w_elmin minimum elevation angle cutoff (usually 7-15 degrees)
-e quoted string of flags that go to data editor (ninja)
here: use minimum arc length of 20 minutes, LC and PC data
-dwght PHASE and RANGE (note order!) data weights in km; usually
LC=1 cm, PC=1 meter
-post_wind Final postfit RANGE and PHASE (note order!) window in km for
edit point cycle (5 sigma)
-pb_min_slip minimum slip for inserting phase bread in postbreak (km)
-pb_min_elev minimum elevation angle at which postbreak criteria are applied
-amb_res Number of iterations for ambiguity resolution with wlpb file
-trop_z_rw random walk parameter for zenith troposphere, negative means
not estimated
-tides tide models to apply to station model. Empty list means no
tides modeled
-orb_clk defines type and location of orbit and clock products for
transmitting satellites
After the run look into run1.err, which contains the error messages of gd2p.pl.
You will have several errors getting the command line options right. Lastly you should end up
with an error like this:
ABBZ not found in s2nml's data base
find the correct command line option in the gd2p.pl -h_model help to change the default sta_info
database to $GEOP555/sta_info and add it to the command string;
re-run.
Theoretically, you should have these files in your directory now:
redoubt:/data/GEOP555/gps/lab04/run1> ls abbz2000.15S EDIT_POINT_FAILURE postbreak_postEdit.log.0 rgfile smooth_post_amb.nio wash accume.nio edtpnt2_ambig.nml postfit2.nio run1.err smsol2.nio wash.nml accume_post_amb.nio GPS_antcal_ref Postfit_amb.sum run1.log smsol.nio wlpb ambigon.log logs postfit.nio run_again Sum_postbreak_logs amb_res_default.nml point.txt Postfit.sum shadow tdp_clk_yaw aregres.nio pos prefilter.txt smcov2.nio tdp_final batch.out.0 postbreak.log.0 qmfile smcov.nio tdp_final_pre_amb batch.txt postbreak.nml qregres.nml smooth.nio tpnml
That's a lot of files. They fall into several categories: log files, intermediate results, results. Most important
for you will be the run1.log run1.err files that you created as they give you hints as to
where to trouble shoot. run_again is a shell script that gd2p.pl creates for you to rerun
the same solution, or edit it without having to edit the commandline history (make a copy of the file).
Obviously, there's trouble! EDIT_POINT_FAILUE (look inside) tells us that the "wash" cycle didn't
converge. We have large phase (LC) post-fit residuals and a large number of outliers:
$> cat Postfit.sum
Plot residuals
Lets generate plots of the phase and code residuals. Call the program
$> residuals.plwhich creates a file called
residuals.txt. Now separate the LC (GIPSY code 120) and PC (GIPSY code 110) residuals:
$> awk '{if($4==120) print $0}' residuals.txt | cl h1 5 > run1_lc_res.txt
$> awk '{if($4==110) print $0}' residuals.txt | cl h1 5 > run1_pc_res.txt
Note that cl is a script to manipulate columnar data that comes with GIPSY; the h1 command converts
the time into elapsed hours, the 5 selects the 5th column of the residuals.txt file, which is the postfit residual
in cm. What does the awk command do?
Generate the plots of the residuals
$> gnup -p run1_lc_res.txt -xl 'Hours' -yl 'postfit LC Residuals (cm)'Or use Matlab, or anything else. Typical LC RMS of residuals is smaller than 1cm; for PC it is 20-80 cm.
Despite that, let's look at the station's position, which is buried in the file tdp_final.
This file contains the final parameter estimates:
- receiver clock is in field STA BIAS (km)
- phase biases per satellite PB GPSXX (km)
- station position STA X, STA Y, STA Z (km)
- etc ...
You can get the position estimate from the file (in km) through:
$> grep "STA [XYZ]" tdp_final
How does this compare to the estimate from the previous lab (in ECEF), what could be
reasons for the differences?
Deliverables: (submit via canvas!)
- the files:
sta_id, sta_pos, sta_svec - your
run_againscript - plots of LC, PC residuals
- answers to questions in bold
rg <at> nmt <dot> edu | Last modified: September 13 2017 19:50.